
目录
数组、链表、栈和队列是四种基础数据结构,他们是高级、复杂的数据结构和算法的基础。本篇先来讲述数组,链表,及算法的优化策略。
数组
定义
数组:数组是一种线性表数据结构,它用一组连续的内存空间存储一组具有相同类型的数据。
定义中有三个关键词:
- 线性表
- 连续的内存空间
- 相同类型数据
"线性表"意思的就是数据排列像一条直线,它只有前后两个方向。"连续的内存空间"和"相同类型的数据"组成了数组的一个重要特性,即"随机访问",随机访问具体指的是:支持在时间复杂度内按照下标快速访问数组的数据。不过有利有弊,这个特性也就导致了数组的插入和删除操作变得很低效。
这里我们需要知道为什么它可以根据下标快速访问数据?这里就需要一个很重要公式 -- 寻址公式:
计算机在分配数组时,当知道数组大小是多少后,就会分配一块连续的内存空间,这时一定有一个这个数组的首地址,然后根据数组中的数据类型分配每一个元素的存储空间,元素大小记为。然后就可以直接根据寻址公式找到对应下标的元素。
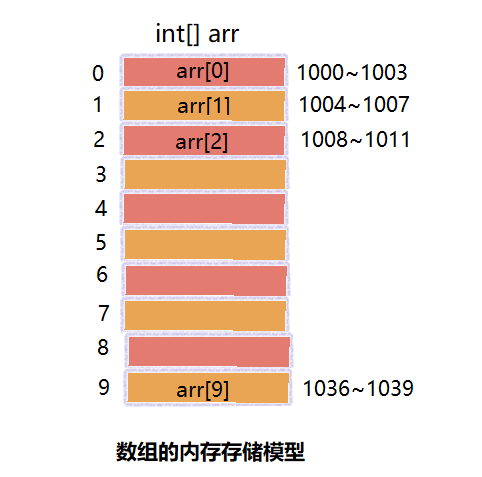
例如,声明了一个int数组arr,长度为10,数组首地址为1000,那么第一个元素的地址为1000~1003,第个元素的地址则为
那么假设我要找arr[4],有寻址公式直接就可以算出其内存地址为1016~1019。
数组的插入和删除
先说一说插入操作: 假设现有在有长度为的数组,若要将一个数据插入到数组的第个位置,为了把第个位置腾出来给新来的数据,我们需要将第~的这部分数据全部向后移动一位,可以计算一下该操作的时间复杂度:
- 最好时间复杂度:若插入到数组末尾,不需要移动数据,则最好时间复杂度为。
- 最坏时间复杂度:若插入到数组开头,则所有数据一次向后移动一位,则最坏时间复杂度为。
- 平均时间复杂度:因为在每个位置插入的概率是相同的,则平均时间复杂度为。
当数组无排序要求,当没有要求数据有序时,那么上述问题可以这样优化:
将第位数据直接移动到数组的末尾,然后新数据放到第位就可以,这样就避免了大量的数据移动。
这样操作,数组的插入操作的时间复杂度就变为了。快速排序算法就用到了这种处理思路。
再说一下删除操作: 同样的前提,如果我们需要删除第位元素,则删除之后,则需要将原来~位的数据全部向前移动一位,那么它的时间复杂度是:
- 最好时间复杂度:若删除的是数组末尾的数据,不需要移动数据,则最好时间复杂度为。
- 最坏时间复杂度:若删除的数据是数组第一位,则所有数据一次向前移动一位,则最坏时间复杂度为。
- 平均时间复杂度:每个位置删除的概率也是相同的,则平均时间复杂度计算后为。
当某些场景下,不强制要求连续性,那么上述问题可以这样优化:
每次删除时并不真正的删除数据,而是标记数据已经被删除,然后当数组中没有更多的存储空间时,集中触发一次真正的删除操作,这样就能大大提升效率。
这个处理思路是不是听着很耳熟?没错,高级语言的GC功能的核心思想就是这样。
链表
上文介绍到数组是一种线性表数据结构,它用一组连续的内存空间存储一组具有相同类型的数据,现在要讲解的链表也是一种线性表数据结构,但它不需要一组连续的内存空间,它通过"指针"将一组零散的内存块(在链表中称之为"节点")串联起来,所以链表的这种特殊数据结构就非常擅长"插入","删除"操作。
单链表
在链表中,为了将所有的节点串联起来,每个节点除存储数据本身之外,还需要额外存储下一个节点的地址,我们把这个记录下一个节点地址的指针称作Next指针(后继指针)。
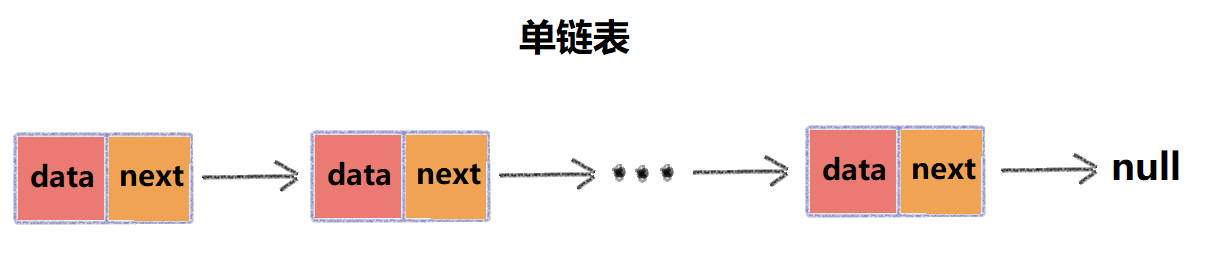
从上图中可以看出,其中有两个节点比较特殊,他们分别是第一个节点和最后一个节点,我们把第一个节点称作头节点,把最后一个节点称作尾节点,其中,头节点用来记录链表的基地址,也就是起始地址,从头节点开始可以遍历整个链表,尾节点是链表最后一个节点,他的next指针不是指向下一个节点,而是指向一个空地址。
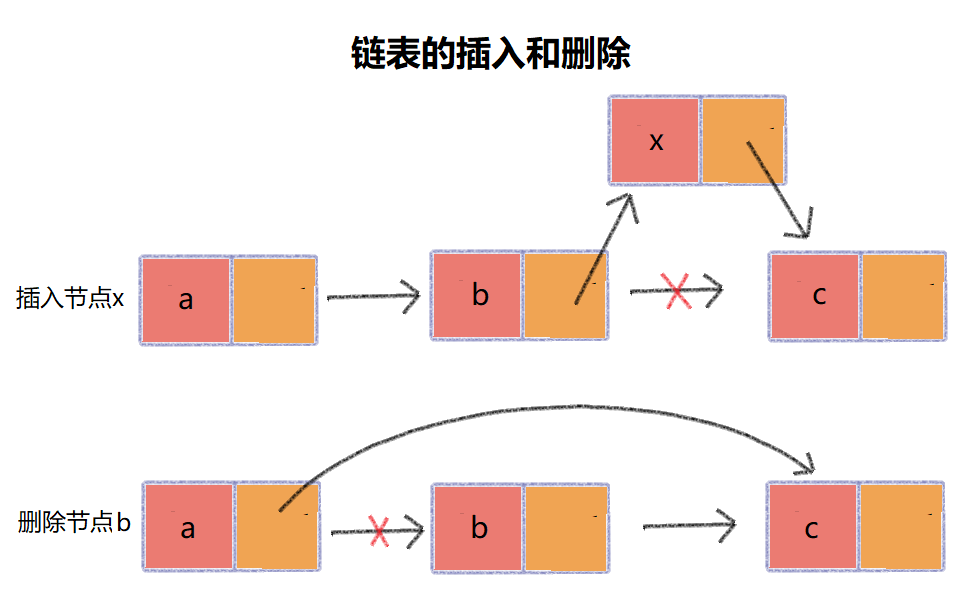
对比数组的插入和删除操作的时间复杂度是,链表的插入和删除操作只需要操作节点的next指针,时间复杂度位,所以它更高效,如下图:
提示
需要注意的是,链表的删除能够实现时间复杂度为的条件是是先知道了节点b的前驱节点a,通过操作前驱节点a就可以实现删除节点b,否则,我们需要遍历链表找到节点b的前驱节点a,其根本原因是链表的内存不是连续的,无法根据寻址公式和下标直接找到对应元素。
所以若要遍历去找删除元素的前驱节点,那么时间复杂度就变为了。
循环链表
循环链表是一种特殊的单链表,它与单链表唯一的区别就在于尾节点。
单链表的尾节点的next指针指向的是空地址,表示其就是最后一个节点,而循环链表的尾节点next指针指向链表的头节点,这样就变成了一个"首尾相连的环",如下图所示:
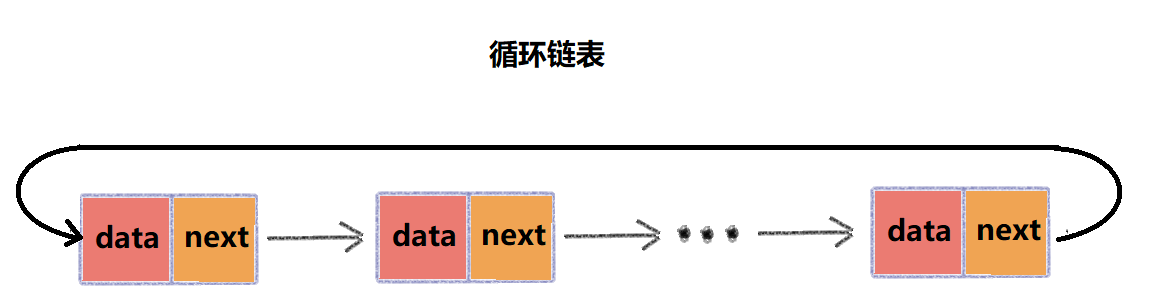
循环链表的优点就是链尾遍历到链首很方便,当处理的数据具有环形结构特点时,适合采用循环链表,例如著名的约瑟夫问题。
双向链表
单链表只有一个遍历方向,从前往后,每个节点只有一个next指针(后继指针),用来指向后一个节点,而双向链表支持两个遍历方向,每个节点不只有next指针,还有prev指针(前驱指针),用来指向前一个节点,如下图:

从图中也可以看出,存储同样多的数据,因为prev指针的存在,双向链表要比单链表占用更多的空间,但是其好处是双向链表支持在时间复杂度找到某一个节点的前驱节点,所以在某些情境下,双向链表的插入,删除等操作,要比单链表简单和高效。
在一般场景中,从链表中删除一个数据有两种方式
- 删除“值等于给定值”的节点。
- 删除给定指针指向的节点。
对于第一种情况(删除“值等于给定值”的节点),无论单链表还是双向链表,都需要从链表的头节点开始一次遍历并对比,只到找到值给与给定值的节点,然后通过上边说的链表删除的方式将其删除。
但是上述操作中仅仅只有删除的动作的时间复杂度为,其找到值给与给定值的节点的动作对应的时间复杂度为,因此,无论时单链表还是双向链表,第一种情况对应的时间复杂度为。
对于第二种情况(删除给定指针指向的节点),尽管已经找到要删除的节点,但是删除动作需要知道该节点的前驱节点。
单链表并不支持直接获取其前驱节点,因此仍需遍历找到其前驱节点,那么单链表的在删除给定指针指向的节点的情况下的时间复杂度仍然为。
双向链表中的节点已经保存了其前驱节点的指针,因此双向链表在删除给定指针指向的节点的情况下的时间复杂度为。
同理,在某个结点前插入一个节点的操作,双向链表也比单链表更有优势。
双向循环链表
顾名思义,如果把循环链表和双向链表结合在一起,就形成了一种新的链表结构,双向循环链表,如下图:
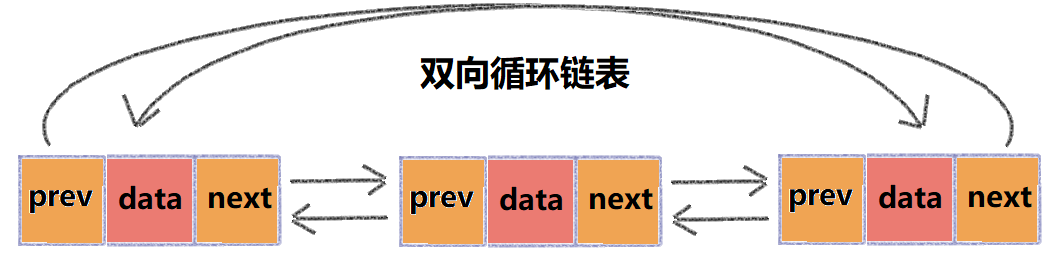
可以看到双向循环链表会占用更多的内存,进而优化了单链表的在插入或删除操作的时间复杂度。这体现出了一个重要的设计思想,那就是以空间换时间。
有了以空间换时间,反之就会有以时间换空间。两者都可以称之为算法在不同条件下的“优化策略”。
算法的优化策略
以空间换时间
"以空间换时间"的核心思想是在程序的执行过程中,通过增加内存或者其他资源的使用量,来减少算法的时间复杂度,从而提高程序的执行效率。
常见的以空间换时间的优化策略包括:
-
缓存技术:将计算结果缓存到内存中,下次请求时直接读取缓存数据,避免重复计算,从而提高程序的执行效率。
-
哈希表:哈希表可以实现快速的查找和删除操作,但需要占用额外的内存空间。因此,在空间充足的情况下,使用哈希表来提高程序的执行效率是一种很好的选择。
-
预处理技术:对于某些耗时的计算任务,我们可以通过预处理的方式将计算结果预先计算出来,并将其存储在内存中。这样,在程序的执行过程中,就可以直接读取预处理后的结果,而不需要重新计算,从而提高程序的执行效率。
-
动态规划:动态规划算法通常需要使用一个二维数组来存储中间结果,这会增加额外的空间开销。但是,使用动态规划算法可以将原本的指数级时间复杂度降为多项式级别,从而提高程序的执行效率。
以时间换空间
"以时间换空间"的核心思想是在程序的执行过程中,通过增加算法的时间复杂度来减少内存或其他资源的使用量,从而提高程序的执行效率。
常见的以时间换空间的优化策略包括:
-
延迟计算:在某些情况下,我们可以将计算操作延迟到需要使用时再进行,而不是在数据结构初始化时就进行计算。
-
懒加载:和延迟计算类似,懒加载也可以将数据的加载操作推迟到需要使用时才进行。
-
压缩算法:在处理大规模数据时,可以使用压缩算法来减少数据的存储空间。
-
迭代器:使用迭代器可以避免一次性加载所有的数据,而是按需生成数据。
总结
在实际开发过程中,以上两种算法优化策略需要根据软件运行环境或业务场景去做抉择,例如一些追求代码执行效率的场景,可以选择以空间换时间(空间复杂度较高,时间复杂度较低的算法或数据机构),相反,如果运行环境内存很小,例如代码运行再手机或者单片机上,这个时候需要选择时间换空间的策略。
参考资料
[1] 数据结构与算法之美 / 王争 著. --北京:人民邮电出版社,2021.6
本文作者:Peter.Pan
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!