
目录
引言
最近看一些代码的时候,发现有人用 System.Collections.Concurrent 下的 BlockingCollection 很便利的实现了生产者 - 消费者模式,这是之前没有注意到的,之前只关注过 ConcurrentQueue<T> 、ConcurrentStack<T> 或 ConcurrentBag<T>这些并发队列,并发堆栈,并发包相关的使用,正好好奇 BlockingCollection的用法,本次将 System.Collections.Concurrent 下的所有用法都实践一下。
简介
那先来看一下该库都有哪些成员从微软官方文档看一下 System.Collections.Concurrent [1]的介绍:
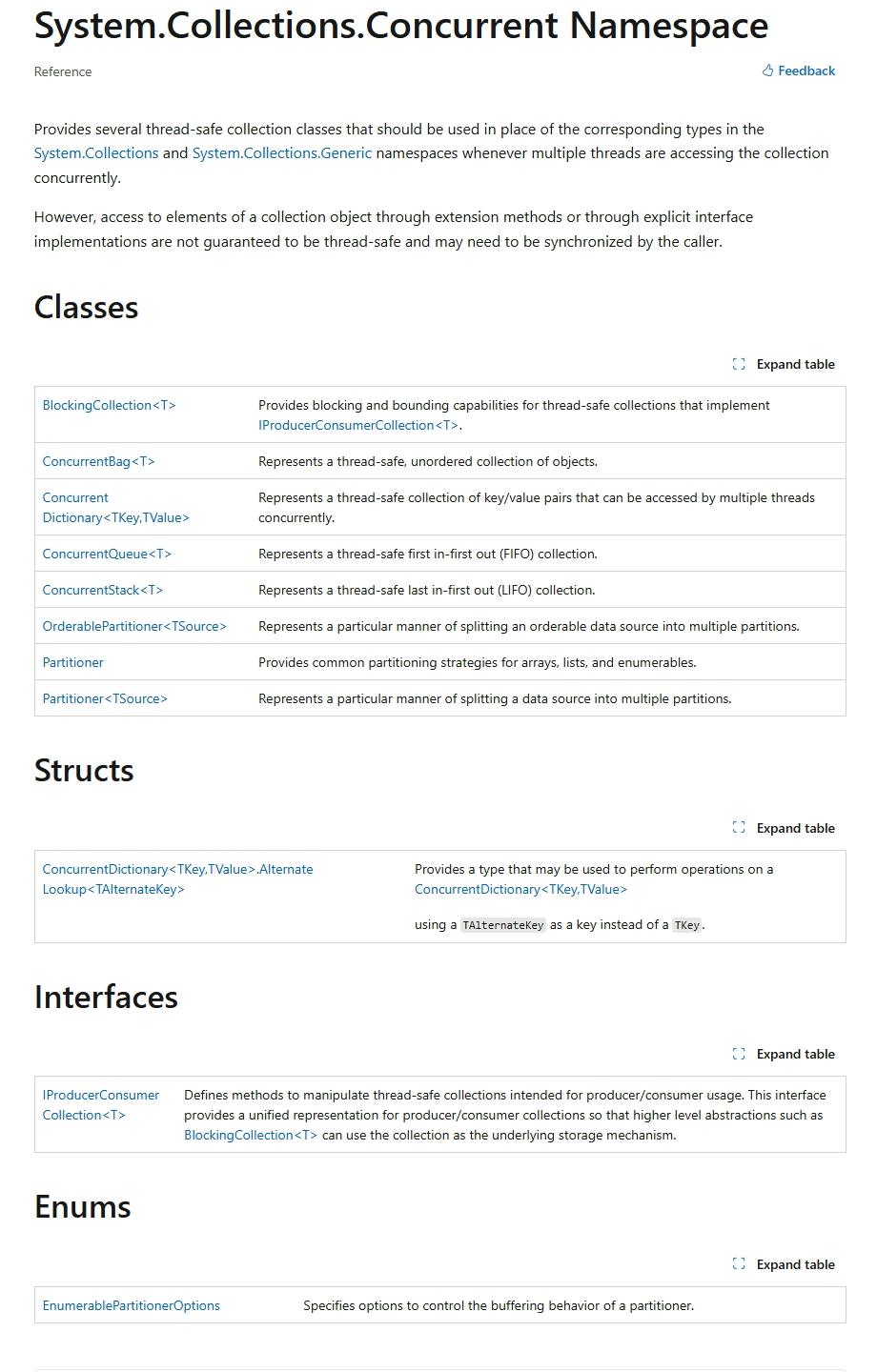
共有如下成员,类成员包含:
- BlockingCollection:为实现了IProducerConsumerCollection接口的集合提供阻塞和限制功能,可用于生产者 - 消费者场景。
- ConcurrentBag:无序的、线程安全的集合,适合于生产者 - 消费者模式,允许快速添加和移除元素。
- ConcurrentDictionary<TKey,TValue>:线程安全的键值对集合,支持多个线程同时读写操作,避免了锁竞争带来的性能问题。
- ConcurrentQueue:线程安全的先进先出(FIFO)队列,支持多个线程同时入队和出队操作。
- ConcurrentStack:线程安全的后进先出(LIFO)栈,支持多个线程同时入栈和出栈操作。
- OrderablePartitioner:抽象类,用于对数据源进行分区,生成有序的分区,方便并行处理。
- Partitioner:提供创建分区程序的静态方法,可用于并行处理时对数据源进行分区。
- Partitioner:抽象基类,用于创建自定义的分区程序。
结构包含:
- ConcurrentDictionary<TKey,TValue>.AlternateLookup:ConcurrentDictionary<TKey, TValue>类的嵌套结构,用于提供替代键查找功能。
接口包含:
- IProducerConsumerCollection:定义了生产者 - 消费者集合的基本操作,如添加、移除元素等,实现该接口的集合可以用于多线程环境。
枚举包含
- EnumerablePartitionerOptions:用于指定在创建可枚举分区程序时的选项,如是否保留元素顺序等。
代码实操
我们从上至下的来看,先来看接口。
IProducerConsumerCollection
看一下该接口的接口说明,主要提供四个方法, CopyTo、ToArray、TryAdd、TryTake,那对于该库中的 BlockingCollection 、ConcurrentQueue 、ConcurrentStack等线程安全的集合,均基于该接口实现。
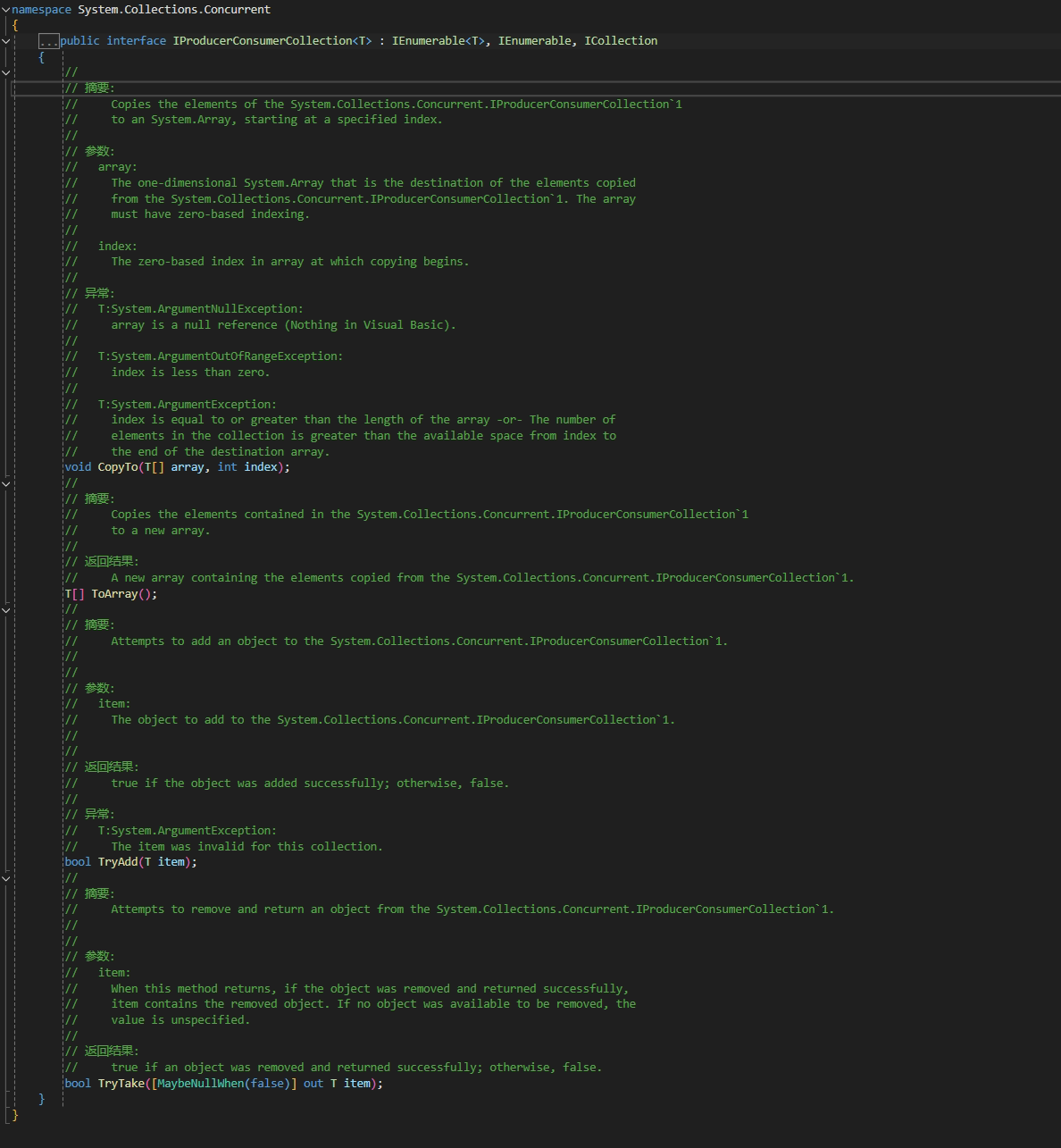
那接下来基于该接口,我们自己手动简单实现一个线程安全的随机取元素的集合:
csharppublic class CustomRandomConCurrentList<T> : IProducerConsumerCollection<T>
{
private readonly Random random = new Random();
private readonly List<T> _items = new List<T>();
private readonly object _lock = new object();
// 添加元素到集合中
public void Add(T item)
{
lock (_lock)
{
_items.Add(item);
}
}
// 尝试添加元素到集合中
public bool TryAdd(T item)
{
lock (_lock)
{
_items.Add(item);
return true;
}
}
// 尝试从集合中移除一个元素
public bool TryTake(out T item)
{
lock (_lock)
{
if (_items.Count > 0)
{
var index = random.Next(0, _items.Count);
item = _items[index]; // 随机取一个元素
_items.RemoveAt(index);
return true;
}
item = default;
return false; // 集合为空,无法移除
}
}
// 获取集合中的元素数量
public int Count
{
get
{
lock (_lock)
{
return _items.Count;
}
}
}
// 获取集合是否为只读
public bool IsSynchronized => false;
// 获取同步根对象(本实现不支持)
public object SyncRoot => throw new NotSupportedException("SyncRoot is not supported.");
public void CopyTo(T[] array, int index)
{
lock (_lock)
{
_items.CopyTo(array, index);
}
}
// 实现 IEnumerable<T> 的 GetEnumerator 方法
public IEnumerator<T> GetEnumerator()
{
lock (_lock)
{
foreach (var item in _items)
{
yield return item;
}
}
}
// 实现 IEnumerable 的非泛型 GetEnumerator 方法
IEnumerator IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
// 将集合转换为数组
public T[] ToArray()
{
lock (_lock)
{
return _items.ToArray();
}
}
// 复制集合中的元素到数组
public void CopyTo(Array array, int index)
{
lock (_lock)
{
((ICollection)_items).CopyTo(array, index);
}
}
}
从上述实现中,可以看到实现的方法明显不止四个,是因为 IProducerConsumerCollection接口还分别继承了IEnumerable<T>, IEnumerable, ICollection 接口,这些接口分别包含以下成员:
-
IEnumerable包含非泛型GetEnumerator(); -
ICollection包含Count、IsSynchronized、SyncRoot、CopyTo; -
IEnumerable<T>包含泛型方法GetEnumerator();
接下来执行测试代码,测试一下,这里说明一下,如何验证这个集合是线程安全的呢?
一般是模拟高并发场景下对集合的大量操作。例如,通过多个线程不断地向队列中添加和取出元素,持续一段时间后,观察集合是否有异常或崩溃,另一方面观察集合内数据是否有丢失、重复或错误的情况。
我们这里简单的模拟生产-消费场景,检查结束后集合是否清空。
csharppublic static void TestCustomRandomConCurrentList()
{
const int ThreadCount = 10; // 线程数
const int OperationsPerThread = 1000; // 每个线程操作次数
var list = new CustomRandomConCurrentList<int>();
int totalAdded = 0;
int totalRemoved = 0;
List<Task> producers = new List<Task>();
List<Task> consumers = new List<Task>();
for (int i = 0; i < ThreadCount; i++)
{
var task = Task.Run(() =>
{
for (int i = 0; i < OperationsPerThread; i++)
{
list.Add(i);
//Console.WriteLine($"producers:{i}");
Interlocked.Increment(ref totalAdded);
}
});
producers.Add(task);
}
//先让生产者生成部分数据,验证是否是随机取出
var temp = Task.Run(() => { Thread.Sleep(10); });
temp.Wait();
for (int i = 0; i < ThreadCount; i++)
{
var task = Task.Run(() =>
{
for (int i = 0; i < OperationsPerThread; i++)
{
if (list.TryTake(out int item))
{
Interlocked.Increment(ref totalRemoved);
//Console.WriteLine($"consumers:{item}");
}
}
});
consumers.Add(task);
}
// 等待所有任务完成
Task.WaitAll(producers.Concat(consumers).ToArray());
// 验证结果
Console.WriteLine($"共添加数据: {totalAdded}, 共移除数据: {totalRemoved}");
Console.WriteLine($"任务结束后剩余数据: {list.Count}");
Console.WriteLine($"集合是否是线程安全:{totalAdded == totalRemoved || list.Count == 0}");
}
输出为:
shell共添加数据: 10000, 共移除数据: 10000 任务结束后剩余数据: 0 集合是否是线程安全:True
移除 Console.WriteLine 注释后,运行后可以看到是随机取出的,若将 CustomRandomConCurrentList<int> 替换为ConcurrentBag<int>,从输出则可以看出是顺序取出的,这里就不放出输出结果了。
至此,手动简单实现一个线程安全的随机取元素的集合就完成了。
ConcurrentQueue
接下来看看线程安全的队列,ConcurrentQueue 先进先出(FIFO)队列,支持多个线程同时入队和出队操作。
csharp// 创建一个空的 ConcurrentQueue
ConcurrentQueue<int> queue = new ConcurrentQueue<int>();
// 入队操作
queue.Enqueue(1);
queue.Enqueue(2);
queue.Enqueue(3);
Console.WriteLine($"队列中有元素:{string.Join(",", queue)}");
//查看队列的头部元素
int peekResult;
if (queue.TryPeek(out peekResult))
{
Console.WriteLine($"查看队列的头部元素: {peekResult},队列中剩余元素:{string.Join(",", queue)}");
}
else
{
Console.WriteLine($"查看队列的头部元素:队列为空");
}
//出队操作
int result;
for (int i = 0; i < 4; i++)
{
if (queue.TryDequeue(out result))
{
Console.WriteLine($"队列取出元素: {result},队列中剩余元素:{string.Join(",", queue)}");
}
else
{
Console.WriteLine("队列取出元素:队列为空");
}
}
//查看队列的头部元素
if (queue.TryPeek(out peekResult))
{
Console.WriteLine($"查看队列的头部元素: {peekResult},队列中剩余元素:{string.Join(",", queue)}");
}
else
{
Console.WriteLine($"查看队列的头部元素:队列为空");
}
结果输出
shell队列中有元素:1,2,3 查看队列的头部元素: 1,队列中剩余元素:1,2,3 队列取出元素: 1,队列中剩余元素:2,3 队列取出元素: 2,队列中剩余元素:3 队列取出元素: 3,队列中剩余元素: 队列取出元素:队列为空
-
使用
Enqueue方法可以将元素添加到队列的末尾,上述代码添加了三个元素 -
使用
TryPeek方法用于尝试查看队列的头部元素,但不会将其移除。如果队列为空,该方法会返回 false,上述代码中,添加三个元素之后,获取到了头部元素,移除全部元素后,再次获取头部元素,未获取到且不抛异常。 -
使用
TryDequeue方法是取出队列头部元素,并从队列中移除,从输出可以看到,取出三次后,队列为空。
如果感兴趣的朋友想要验证 ConcurrentQueue 的并发测试,可以接着使用上面的测试代码,将 CustomRandomConCurrentList<int> 更改为 ConcurrentQueue<int> ,然后将 Add、TryTake 方法分别替换为 Enqueue、 TryDequeue,即可直接运行测试代码。
ConcurrentStack
接下来是线程安全的堆栈,ConcurrentStack 是线程安全的后进先出(LIFO)栈,支持多个线程同时入栈和出栈操作。
csharp// 创建一个空的 ConcurrentStack
ConcurrentStack<int> stack = new ConcurrentStack<int>();
// 压栈操作
stack.Push(1);
stack.Push(2);
stack.Push(3);
Console.WriteLine($"堆栈中有元素:{string.Join(",", stack)}");
//查看堆栈的头部元素
int peekResult;
if (stack.TryPeek(out peekResult))
{
Console.WriteLine($"查看堆栈的头部元素: {peekResult},堆栈中剩余元素:{string.Join(",", stack)}");
}
else
{
Console.WriteLine($"查看堆栈的头部元素:堆栈为空");
}
//出栈操作
int result;
for (int i = 0; i < 4; i++)
{
if (stack.TryPop(out result))
{
Console.WriteLine($"堆栈取出元素: {result},堆栈中剩余元素:{string.Join(",", stack)}");
}
else
{
Console.WriteLine("堆栈取出元素:堆栈为空");
}
}
//查看堆栈的头部元素
if (stack.TryPeek(out peekResult))
{
Console.WriteLine($"查看堆栈的头部元素: {peekResult},堆栈中剩余元素:{string.Join(",", stack)}");
}
else
{
Console.WriteLine($"查看堆栈的头部元素:堆栈为空");
}
结果输出:
csharp堆栈中有元素:3,2,1
查看堆栈的头部元素: 3,堆栈中剩余元素:3,2,1
堆栈取出元素: 3,堆栈中剩余元素:2,1
堆栈取出元素: 2,堆栈中剩余元素:1
堆栈取出元素: 1,堆栈中剩余元素:
堆栈取出元素:堆栈为空
查看堆栈的头部元素:堆栈为空
可以看到,他的元素排列顺序和取出顺序都是跟 ConcurrentQueue 是相反的,同样的想要验证 ConcurrentStack 的并发测试,还是使用上面的测试代码,将 CustomRandomConCurrentList<int> 更改为 ConcurrentStack<int> ,然后将 Add、TryTake 方法分别替换为 Push、 TryPop,即可直接运行测试代码。
ConcurrentBag
ConcurrentBag 是无序的、线程安全的集合,许快速添加和移除元素。
csharp// 创建一个空的 ConcurrentBag
ConcurrentBag<int> bags = new ConcurrentBag<int>();
// 入队操作
bags.Add(1);
bags.Add(2);
bags.Add(3);
Console.WriteLine($"并发包中有元素:{string.Join(",", bags)}");
//查看并发包的头部元素
int peekResult;
if (bags.TryPeek(out peekResult))
{
Console.WriteLine($"查看并发包的头部元素: {peekResult},并发包中剩余元素:{string.Join(",", bags)}");
}
else
{
Console.WriteLine($"查看并发包的头部元素:并发包为空");
}
//出队操作
int result;
for (int i = 0; i < 4; i++)
{
if (bags.TryTake(out result))
{
Console.WriteLine($"并发包取出元素: {result},并发包中剩余元素:{string.Join(",", bags)}");
}
else
{
Console.WriteLine("并发包取出元素:并发包为空");
}
}
//查看并发包的头部元素
if (bags.TryPeek(out peekResult))
{
Console.WriteLine($"查看并发包的头部元素: {peekResult},并发包中剩余元素:{string.Join(",", bags)}");
}
else
{
Console.WriteLine($"查看并发包的头部元素:并发包为空");
}
输出:
shell并发包中有元素:3,2,1 查看并发包的头部元素: 3,并发包中剩余元素:3,2,1 并发包取出元素: 3,并发包中剩余元素:2,1 并发包取出元素: 2,并发包中剩余元素:1 并发包取出元素: 1,并发包中剩余元素: 并发包取出元素:并发包为空 查看并发包的头部元素:并发包为空
从输出看,ConcurrentBag 与 ConcurrentStack看着是一样的,但其实他俩在多线程下并不同。最主要的原因就是它一种无序的集合,不保证元素的添加和移除顺序,内部使用一种特殊的算法来管理元素,使得多个线程可以高效地添加和移除元素,适合处理对元素顺序没有要求的集合,且高并发且线程频繁添加/移除的场景下,性能优于其他并发集合。
并发集合对比
那我们将ConcurrentBag 、ConcurrentQueue与 ConcurrentStack这三个并发集合在性能和适用场景做一下对比:
性能特点
ConcurrentBag<T>- 在多线程同时添加和移除元素的场景下性能较好,因为它的设计允许每个线程独立地操作自己的本地存储,减少了线程间的竞争。当线程主要进行添加和移除操作,且对元素顺序无要求时,使用 ConcurrentBag 可以获得较高的性能。
ConcurrentStack<T>- 对于多线程频繁进行入栈(Push)和出栈(Pop)操作的场景,性能表现不错。由于栈的操作主要集中在栈顶,多线程并发操作时的冲突相对较少。
ConcurrentQueue<T>- 在多线程环境下,如果需要保证元素按照添加的顺序被处理,ConcurrentQueue 是合适的选择。不过,由于队列需要维护头部和尾部的指针,在高并发情况下,可能会存在一定的性能开销。
适用场景
ConcurrentBag<T>- 适用于并行计算场景,例如多个线程同时生成任务,然后由其他线程随机获取任务进行处理,不关心任务的处理顺序。 当需要快速收集元素,且后续处理对元素顺序无要求时,也可以使用 ConcurrentBag。
ConcurrentStack<T>- 常用于实现递归算法的迭代版本,例如深度优先搜索(DFS)。多个线程可以同时将节点压入栈中,然后按照后进先出的顺序进行处理。 适用于撤销操作的场景,最后执行的操作可以最先被撤销。
ConcurrentQueue<T>- 适用于任务调度系统,任务按照提交的顺序依次执行。例如,多个线程将任务添加到队列中,然后由一个或多个工作线程从队列中取出任务进行处理。 在消息传递系统中,消息按照发送的顺序依次被处理,也可以使用 ConcurrentQueue 来实现。
ConcurrentDictionary
ConcurrentDictionary 是用于多线程环境下的线程安全字典,用于多线程环境下的并发读写字典操作。
常见用法如下:
- 创建实例
csharpvar dict = new ConcurrentDictionary<string, int>();
- 添加元素
csharp// TryAdd (原子操作)
bool added = dict.TryAdd("key1", 100);
// AddOrUpdate (如果存在则更新,否则添加)
dict.AddOrUpdate("key1", 200, (key, oldValue) => oldValue + 200);
- 获取元素
csharp// TryGetValue (原子操作)
if (dict.TryGetValue("key1", out int value))
{
Console.WriteLine($"Value: {value}");
}
// 直接通过索引器获取(非原子,需自行处理异常)
try
{
var val = dict["key1"];
}
catch (KeyNotFoundException)
{
// 处理不存在的情况
}
- 更新元素
csharp// TryUpdate (原子操作)
bool updated = dict.TryUpdate("key1", 300, 200); // 仅当旧值为200时更新
// 使用 AddOrUpdate 更新
dict.AddOrUpdate("key1", 0, (key, oldValue) => 300);
- 删除元素
csharp// TryRemove (原子操作)
if (dict.TryRemove("key1", out int removedValue))
{
Console.WriteLine($"Removed: {removedValue}");
}
// 删除满足条件的键
dict.TryRemove("key2", out _);
- 获取或添加
csharp// GetOrAdd (原子操作)
int value = dict.GetOrAdd("key3", 400); // 如果不存在则添加
注意事项
使用 ConcurrentDictionary 需要注意的是,再用索引器直接获取元素和遍历元素可能存在问题,下面用代码示例:
-
索引器的线程安全问题
直接通过索引器(
dict[key])读取或写入时,如果其他线程正在修改该键的值,可能引发两个问题,一个是读取时键被删除,然后抛出KeyNotFoundException
csharpstatic ConcurrentDictionary<int, int> dict = new ConcurrentDictionary<int, int>();
static void Main()
{
int count = 0;
while (count < 10)
{
// 清空字典
dict.Clear();
// 初始化一个键值
dict.TryAdd(1, 100);
// 启动一个线程删除键
Task.Run(() => { dict.TryRemove(1, out _); });
// 主线程尝试通过索引器读取
try
{
Console.WriteLine($"通过索引器读取值: {dict[1]}"); // 可能抛出 KeyNotFoundException
}
catch (KeyNotFoundException ex)
{
Console.WriteLine($"异常捕获: {ex.Message}");
}
count++;
}
}
输出:
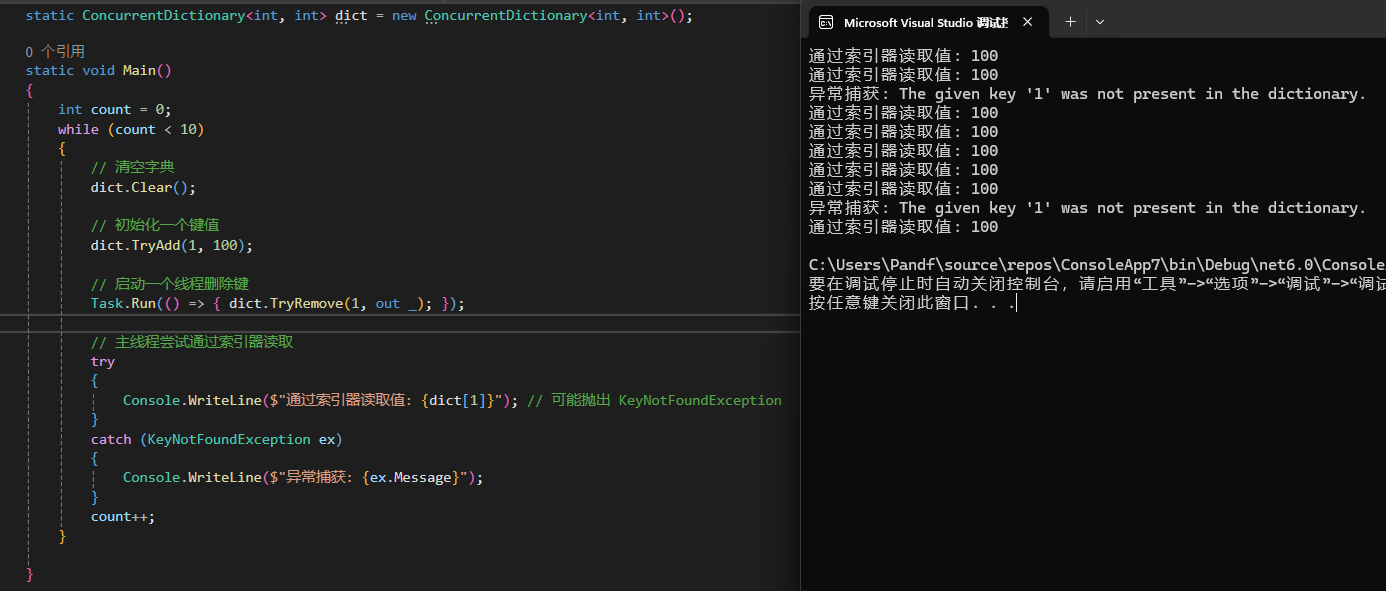
-
遍历元素的线程安全问题
ConcurrentDictionary的枚举器是非快照的,遍历时如果其他线程修改字典,可能也导致遍历过程中看到部分更新的数据。
csharpstatic ConcurrentDictionary<int, int> dict = new ConcurrentDictionary<int, int>();
static void Main()
{
// 初始化数据
for (int i = 0; i < 5; i++)
{
dict.TryAdd(i, i * 10);
}
Random random = new Random();
// 启动一个线程在遍历时修改字典
Task.Run(() =>
{
// 遍历时修改字典
foreach (var key in dict.Keys)
{
dict.TryAdd(key + 100, (key + 100) * 10);
// 模拟耗时操作
Task.Delay(150).Wait();
}
});
foreach (var kv in dict)
{
if (dict.TryGetValue(kv.Key, out int value))
{
Console.WriteLine($"键: {kv.Key}, 值: {value}");
// 模拟耗时操作
Task.Delay(30).Wait();
}
}
Console.WriteLine("遍历完成");
}
输出:
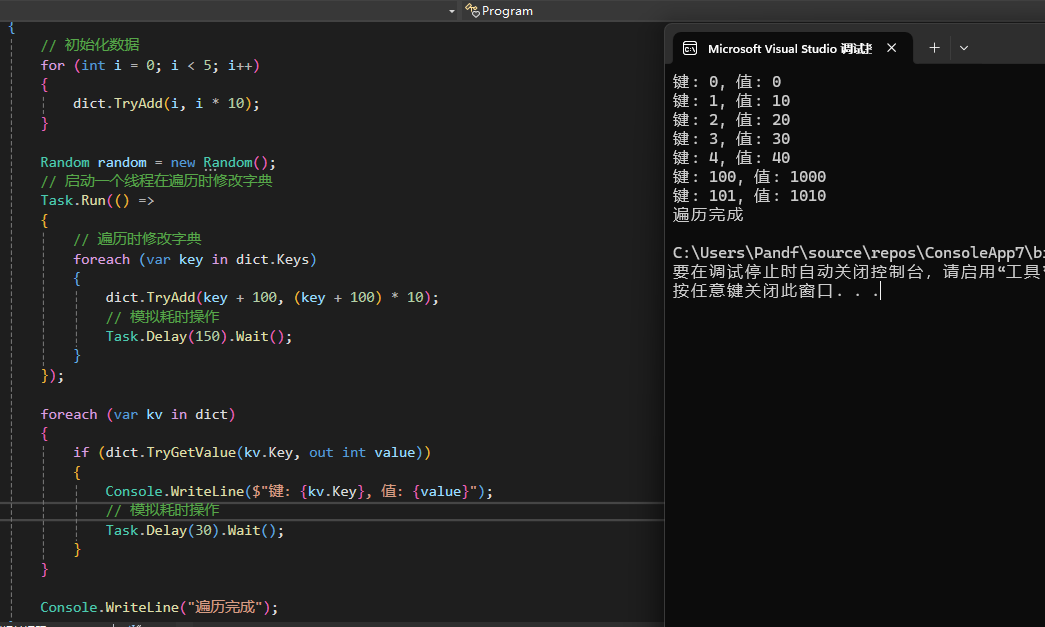
可以看到遍历过程输出了部分新添加的数据。
-
原子操作与索引器的区别
其实就是写入冲突,通过索引器获取到的键值对,值被修改后,可能会覆盖其他线程的更新。
csharpstatic ConcurrentDictionary<int, int> dict = new ConcurrentDictionary<int, int>();
static void Main()
{
// 初始化键
dict.TryAdd(1, 0);
// 启动多个线程通过索引器自增(非原子操作)
Parallel.For(0, 1000, i =>
{
// 危险操作:索引器读取后可能被其他线程修改
int value = dict[1];
dict[1] = value + 1;
});
Console.WriteLine($"通过索引器自增后的值: {dict[1]}"); // 可能小于 1000
// 重置字典
dict.TryRemove(1, out _);
// 启动多个线程使用 AddOrUpdate(原子操作)
Parallel.For(0, 1000, i =>
{
dict.AddOrUpdate(1, 1, (key, oldVal) => oldVal + 1);
});
Console.WriteLine($"通过 AddOrUpdate 自增后的值: {dict[1]}"); // 应为 1000
}
输出:
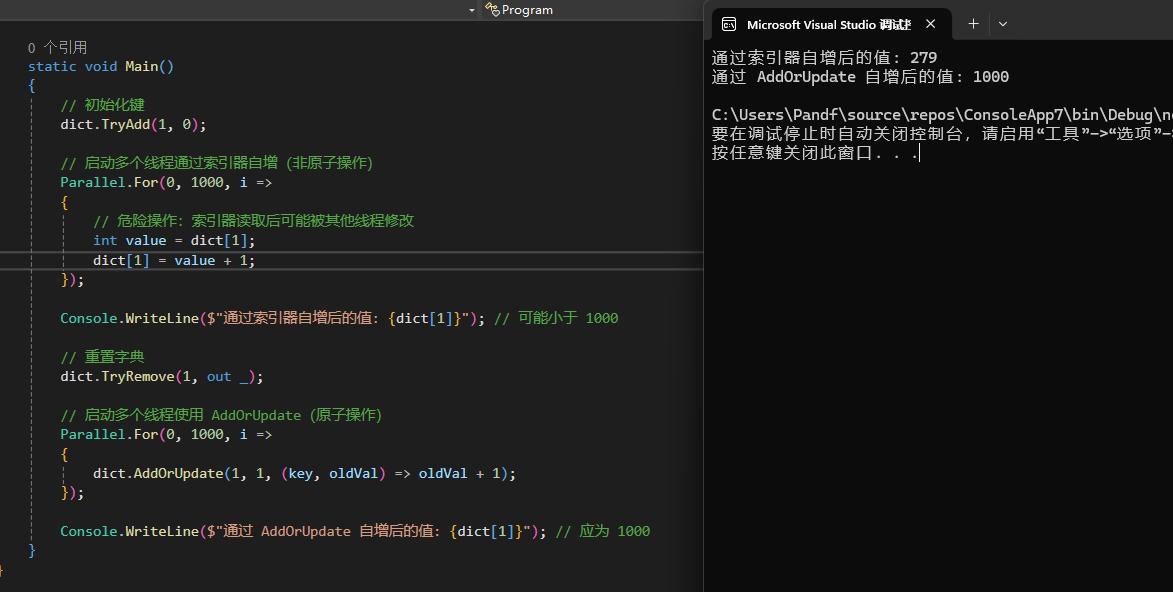 从结果也可以看到,使用索引器自增时,因并发覆盖导致丢失更新,所以最终值可能小于
从结果也可以看到,使用索引器自增时,因并发覆盖导致丢失更新,所以最终值可能小于 1000,而使用 AddOrUpdate 时,最终值始终为 1000。
BlockingCollection
BlockingCollection<T> 是专门用于生产者-消费者模式的并发集合。它提供了以下核心功能:
-
阻塞操作:当集合为空时,消费者线程会被阻塞;当集合已满时(如果设置了容量限制),生产者线程会被阻塞。
-
线程安全:无需额外锁机制即可在多线程环境中使用。
-
封装底层集合:默认使用
ConcurrentQueue<T>(先进先出),但也可以使用其他实现了IProducerConsumerCollection<T>的集合(如ConcurrentStack<T>或者上文中自己实现的CustomRandomConCurrentList<T>)。
下面看一下示例:
csharpRandom random = new Random();
// 方式1:创建 BlockingCollection(默认不限制容量)
var blockingCollection = new BlockingCollection<int>();
// 方式2:创建一个容量为 5 的集合
//var blockingCollection = new BlockingCollection<int>(2);
// 方式3:创建 ConcurrentStack(后进先出)
//var blockingCollection = new BlockingCollection<int>(new ConcurrentStack<int>());
// 生产者任务
Task producer = Task.Run(() =>
{
for (int i = 0; i < 10; i++)
{
blockingCollection.Add(i); // 添加元素
Console.WriteLine($"生产: {i}");
Thread.Sleep(random.Next(20, 200));
}
blockingCollection.CompleteAdding(); // 标记生产者已完成
});
// 消费者任务
Task consumer = Task.Run(() =>
{
foreach (int item in blockingCollection.GetConsumingEnumerable()) // 阻塞直到有数据
{
Console.WriteLine($"消费: {item}");
Thread.Sleep(200);
}
});
Task.WaitAll(producer, consumer);
Console.WriteLine("操作完成");
输出:
shell生产: 0 消费: 0 生产: 1 消费: 1 生产: 2 消费: 2 生产: 3 消费: 3 生产: 4 生产: 5 消费: 4 生产: 6 生产: 7 消费: 5 生产: 8 消费: 6 生产: 9 消费: 7 消费: 8 消费: 9 操作完成
因为上述代码中,使用的默认构造方法,所以使用的是 ConcurrentQueue先进先出的方式取出元素,若修改为方式3后进先出的方式,则输出会像这样,最后生产的,先被消费:
shell生产: 0 消费: 0 生产: 1 生产: 2 消费: 2 生产: 3 生产: 4 消费: 4 生产: 5 消费: 5 生产: 6 消费: 6 生产: 7 生产: 8 消费: 8 生产: 9 消费: 9 消费: 7 消费: 3 消费: 1 操作完成
若采用方式2创建,则会限制生产队列的容量,当队列中满容量且没有被消费时,则阻塞当前线程,直到被消费后,重新生产并加入,输出会像这样:
csharp生产: 0
消费: 0
生产: 1
消费: 1
生产: 2
生产: 3
消费: 2
生产: 4
消费: 3
生产: 5
消费: 4
生产: 6
消费: 5
生产: 7
消费: 6
生产: 8
消费: 7
生产: 9
消费: 8
消费: 9
操作完成
当然也可以创建后进先出,且容量为2的队列,像这样:
csharpvar blockingCollection = new BlockingCollection<int>(new ConcurrentStack<int>(),2);
下面列出部分关键方法或属性:
-
添加元素
-
Add(T item): 添加元素,如果集合已满(有界容量),则阻塞。 -
TryAdd(T item, int timeout): 尝试添加元素,可指定超时时间。
-
-
获取元素
-
Take(): 移除并返回元素,若集合为空,则阻塞。 -
TryTake(out T item, int timeout): 尝试获取元素,可指定超时时间。
-
-
完成通知
-
CompleteAdding(): 标记集合不再接受新元素,后续的 Add 操作会抛出异常。 -
IsCompleted: 返回是否已完成添加且集合为空。
-
-
其他属性
-
BoundedCapacity: 返回集合的容量限制(若为无界,返回 int.MaxValue)。 -
IsAddingCompleted: 返回是否已调用 CompleteAdding()。
-
OrderablePartitioner
OrderablePartitioner<TSource> 是 System.Collections.Concurrent 命名空间下的一个高级分区器类,专门用来并行处理场景,使用者可以用来自定义数据的分区策略,并在 Parallel.ForEach 等并行操作中保持元素的顺序性(例如,处理顺序与原始数据顺序一致)。
通过 Partitioner.Create() 创建分区器时,可以使用 EnumerablePartitionerOptions 指定是否需要缓存,EnumerablePartitionerOptions枚举值区别如下:
EnumerablePartitionerOptions.None:这是默认值,使用系统默认的分区行为。系统会根据集合的类型、大小以及运行环境等因素,自动选择合适的分区策略。通常情况,它会尝试进行高效的分区,以充分利用多核处理器的性能。适用于不确定使用哪种分区策略,或者希望让系统自动优化分区的场景。EnumerablePartitionerOptions.NoBuffering:默认情况下,分区器可能会对数据进行缓冲,以提高性能。但使用NoBuffering时,分区器会逐个元素地将数据分配给工作线程,而不会预先缓冲一批数据。这样工作线程会立即处理下一个可用的元素,减少了内存使用,但可能会增加线程间的同步开销。适用于处理实时数据流时,这种数据是逐个到达的,使用NoBuffering可以避免不必要的缓冲。
示例代码:
csharpint[] data = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int[] result = new int[data.Length];
// 创建 OrderablePartitioner
OrderablePartitioner<int> partitioner = Partitioner.Create(data, EnumerablePartitionerOptions.NoBuffering);
// 并行处理结果
Parallel.ForEach(partitioner, (item, state, index) =>
{
Console.WriteLine($"处理元素开始: {item}, 原始索引: {index},时间:{DateTime.Now.ToString("HH:mm:ss:fff")}");
// 模拟处理逻辑
Thread.Sleep(100);
result[index] = item;
});
Console.WriteLine($"result中的元素为:{string.Join(",", result)},时间:{DateTime.Now.ToString("HH:mm:ss:fff")}");
输出:
shell处理元素开始: 6, 原始索引: 5,时间:14:29:23:015 处理元素开始: 7, 原始索引: 6,时间:14:29:23:019 处理元素开始: 8, 原始索引: 7,时间:14:29:23:019 处理元素开始: 2, 原始索引: 1,时间:14:29:23:019 处理元素开始: 3, 原始索引: 2,时间:14:29:23:019 处理元素开始: 5, 原始索引: 4,时间:14:29:23:019 处理元素开始: 9, 原始索引: 8,时间:14:29:23:015 处理元素开始: 1, 原始索引: 0,时间:14:29:23:015 处理元素开始: 10, 原始索引: 9,时间:14:29:23:015 处理元素开始: 4, 原始索引: 3,时间:14:29:23:015 result中的元素为:1,2,3,4,5,6,7,8,9,10,时间:14:29:23:155
从输出可以看到,因为在每个任务处理时,能够明确知道当前任务的索引,所以也就能够处理使得结果顺序跟源顺序一致,从时间戳来看,完成10个耗时100秒的任务,总时间只用了100多毫秒,充分利用了CPU多线程性能。
总结
上述就是对 System.Collections.Concurrent 命名空间的所有成员做了比较详细的说明和应用了,我们可以通过合理选择这些集合类,可以显著简化多线程编程,同时保证高性能与线程安全。
参考链接
[1] https://learn.microsoft.com/en-us/dotnet/api/system.collections.concurrent?view=net-9.0
本文作者:Peter.Pan
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!