
目录

简介
介绍PaddleOCR之前,先来介绍一下百度的飞桨项目:
百度飞桨(PaddlePaddle) 是百度推出的开源深度学习平台。作为国内领先的深度学习框架之一,飞桨提供了丰富的工具和资源,帮助开发者和研究者轻松地构建、训练和部署各种深度学习模型。他有非常全面的深度学习库,提供了广泛的深度学习库和工具,涵盖了图像处理、自然语言处理、推荐系统等多个领域。开发者可以轻松地使用这些工具构建复杂的深度学习模型。并且它支持灵活的模型定义和训练,使其适用于各种深度学习任务。
而今天我们要来试玩一下他的文字识别模块 --- PaddleOCR。
PaddleOCR是一个非常优质的OCR工具包(实用的超轻量级OCR系统),基于PaddlePaddle,支持80多种语言的识别,提供数据标注和合成工具,支持在服务器、移动设备、嵌入式和物联网设备之间进行训练和部署。旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。


特性
支持多种OCR相关前沿算法,在此基础上打造产业级特色模型PP-OCR和PP-Structure,并打通数据生产、模型训练、压缩、预测部署全流程。

小试牛刀
接下来我们来试玩一下这个PaddleOCR。
安装Python环境
可以直接去官网下载:https://www.python.org/downloads/windows/
我这里下载的是Python 3.11.3 windows 64bit。下载完后可以直接安装。
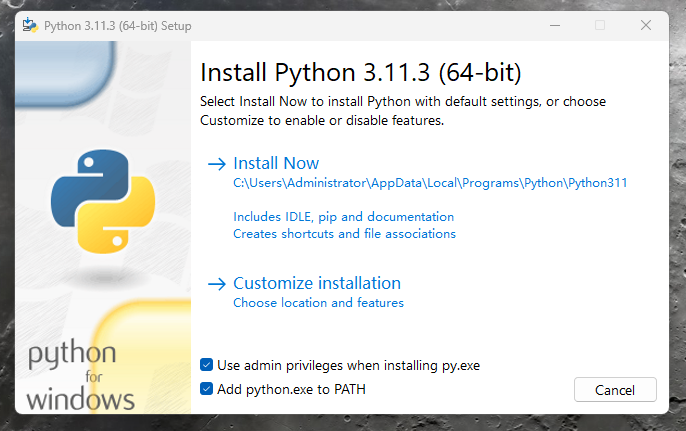
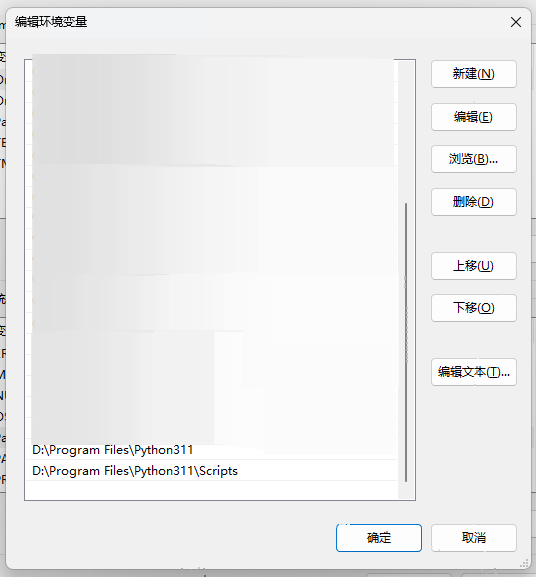
切记一定要勾选最下方”Add python.exe to PATH“,添加环境变量,否则需要手动添加环境变量。
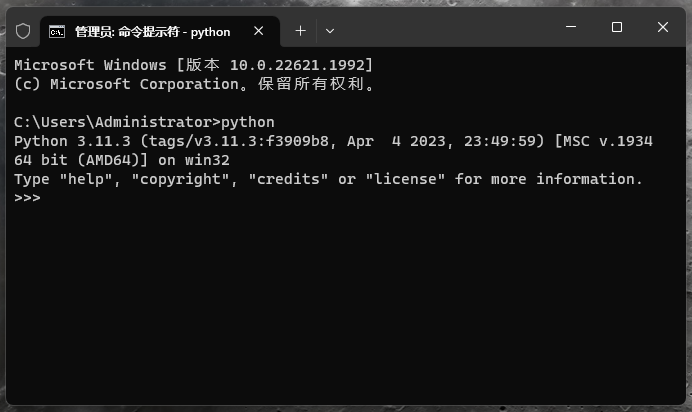
安装完毕后可以再任意位置打开CMD,输入python ,如下则环境安装完成:
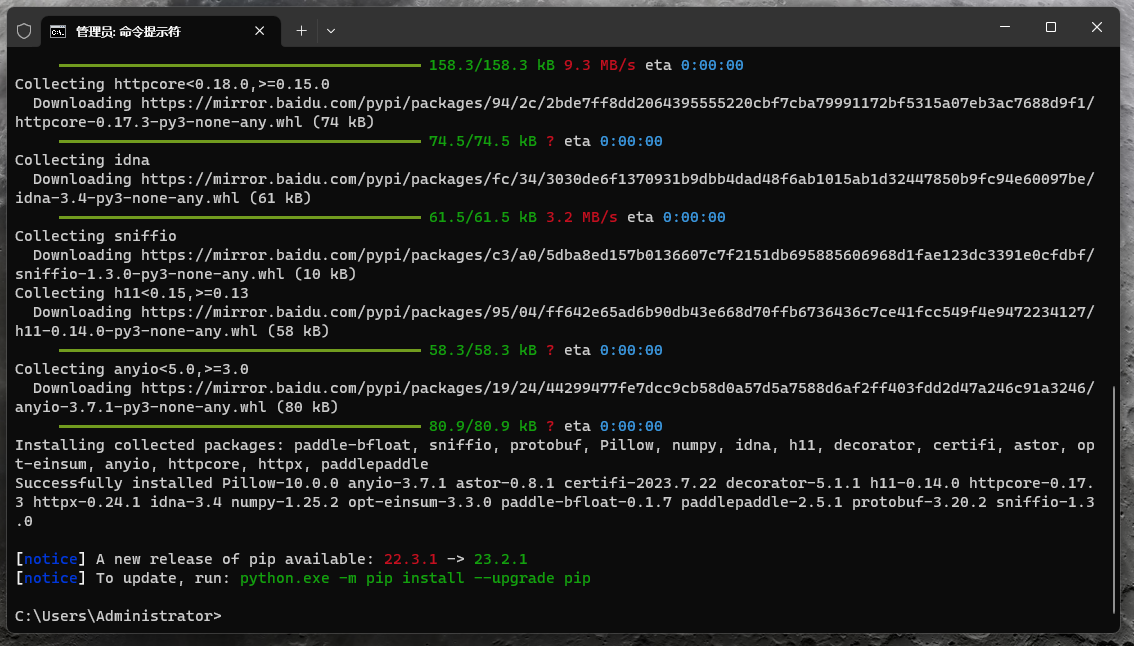
安装PaddlePaddle:
python -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
安装PaddleOCR whl包:
pip install "paddleocr>=2.0.1" --upgrade PyMuPDF==1.21.1
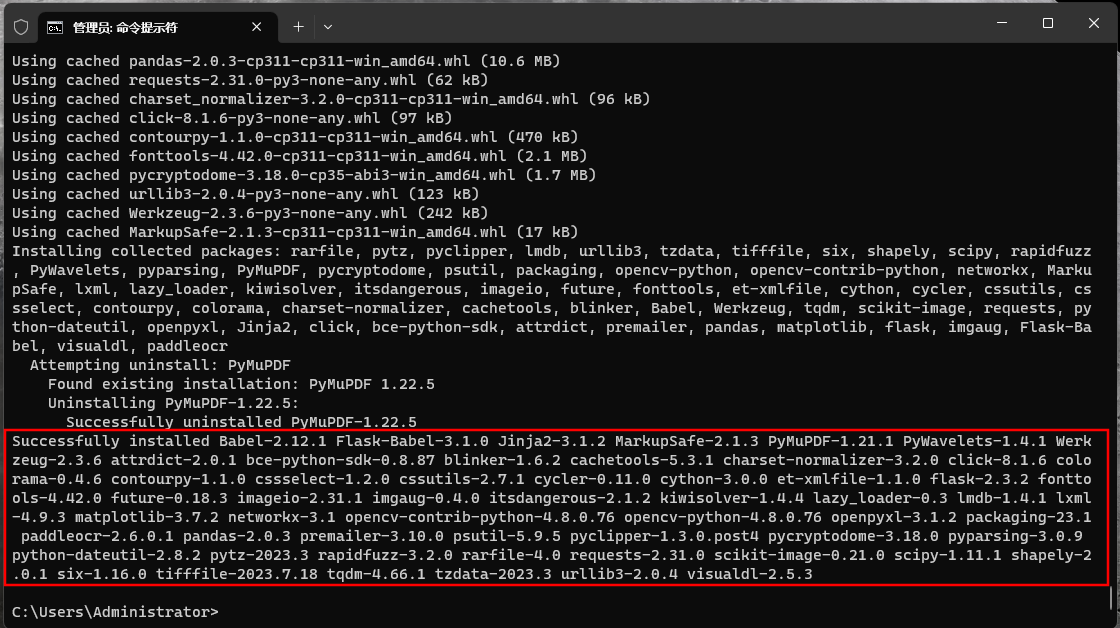
默认安装的PyMuPDF版本有问题,如果不加 --upgrade PyMuPDF==1.21.1 ,则会报错, PaddleOCR whl包含很多依赖包,如下如图中红框所示,所以下载时间较长,可能需要十几二十分钟。
测试
PaddleOCR提供了一系列测试图片,可以下载(https://paddleocr.bj.bcebos.com/dygraph_v2.1/ppocr_img.zip) 并解压
,可以使用他们的测试图片进行测试,也可以自己找一些图片,截图,照片自行测试,我这里找了一本书拍照,导出图片为 book.jpg ,如下:
 来编写python代码,使用
来编写python代码,使用PaddleOCR 识别 book.jpg 并显示识别结果,代码如下:
pythonfrom paddleocr import PaddleOCR, draw_ocr
import cv2
import numpy as np
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
img_path = 'C:/Users/Administrator/Desktop/book.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果(将识别的结果框出并显示识别结果)
from PIL import Image
image = Image.open(img_path).rotate(180)
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts)
im_show = Image.fromarray(im_show)
im_show.save('C:/Users/Administrator/Desktop/result.jpg')
注意,直接运行上述代码可能会报错 module 'numpy' has no attribute 'int'.,原因是新的numpy包中 np.int 已弃用,可以手动降版本解决,在CMD中分别运行如下命令,先卸载,后安装:
shellpip uninstall -y numpy pip install "Numpy==1.23.5"
上述代码中,第一段代码将识别结果打印到了控制台,如下所示:
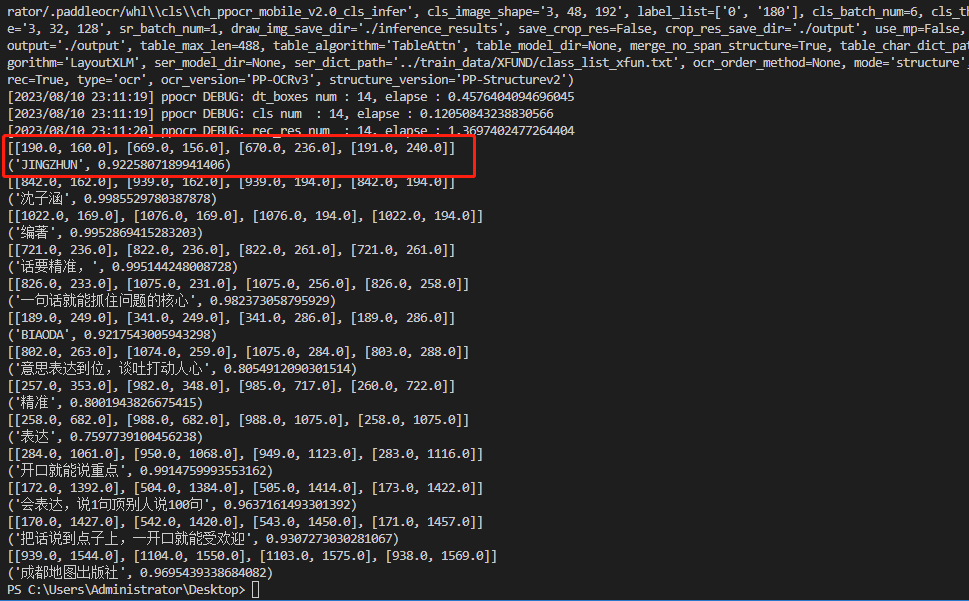
上面红框内的内容就是识别结果,主要有三部分组成:
[[190.0, 160.0], [669.0, 156.0], [670.0, 236.0], [191.0, 240.0]],代表四个点形成的矩形,它框出了要识别的内容。'JINGZHUN',识别后的结果字符串。在源图片中就是书的左上角的拼音。0.9225807189941406,这一串数字代表的匹配度,匹配度越高,代表着识别越准确。
从控制台可以看出来,PaddleOCR的识别结果就是一组这样的数据。
它也提供了API,将这些结果可视化。第二段代码就是使数据可视化,输出结果下图:

小结
第一次玩python,这个demo虽然简单,但也折磨了我四五天,从环境安装(环境变量问题),包安装(PyMuPDF版本问题),python代码调试(包,语法等问题),到输出结果(结果与预期不一致),期间看官方文档,查资料,即使照着官方文档一步一步走,也依然步步是坑,好在达到了我的预期,能简单识别一个图片。但是从上述结果中可以看出,识别还是有些问题的,官方文档说可以通过训练模型,提高准确率。接下来,可以尝试玩一玩自己训练模型。
参考
PaddleOCR运行环境准备:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/environment.md
PaddleOCR快速开始:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/quickstart.md
一文讲通OCR文字识别原理与技术全流程:https://juejin.cn/post/7147218078923751455
本文作者:Peter.Pan
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!